Сбор семантического ядра сайта на заказ: узнайте какими запросами потенциальные клиенты ищут продукт
Соберем список ключевых запросов для SEO и контекстной рекламы, гарантированно найдем еще +10-300 точек входа клиентов в ваш бизнес через запросы в поисковых системах

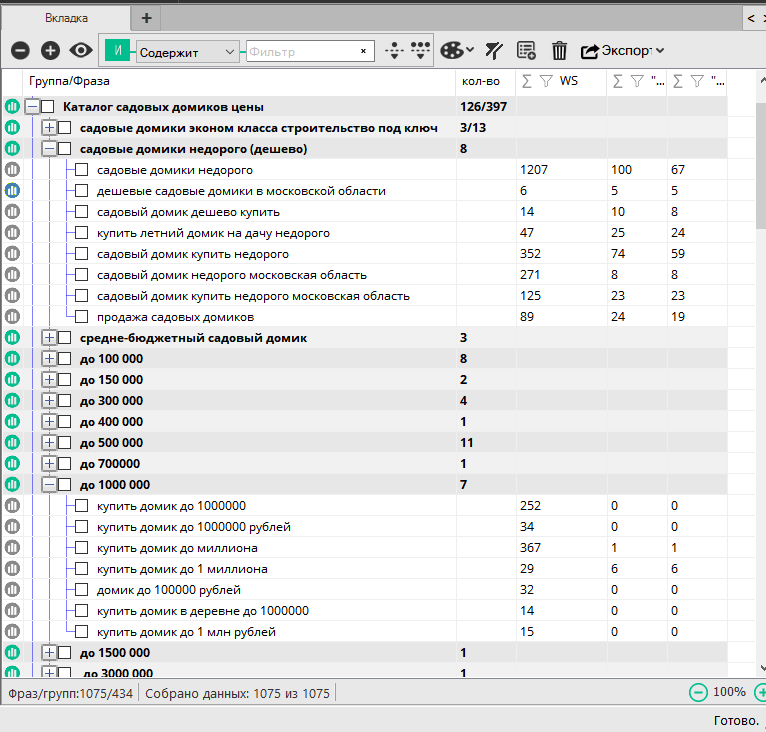
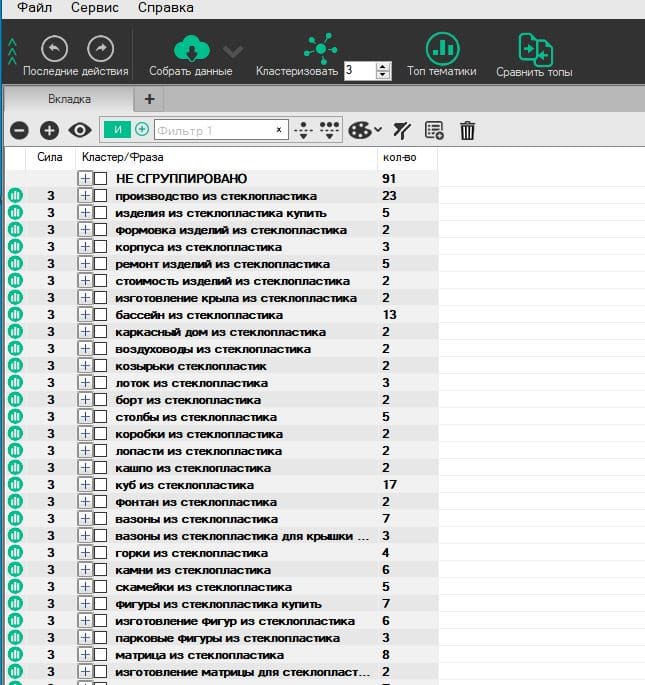
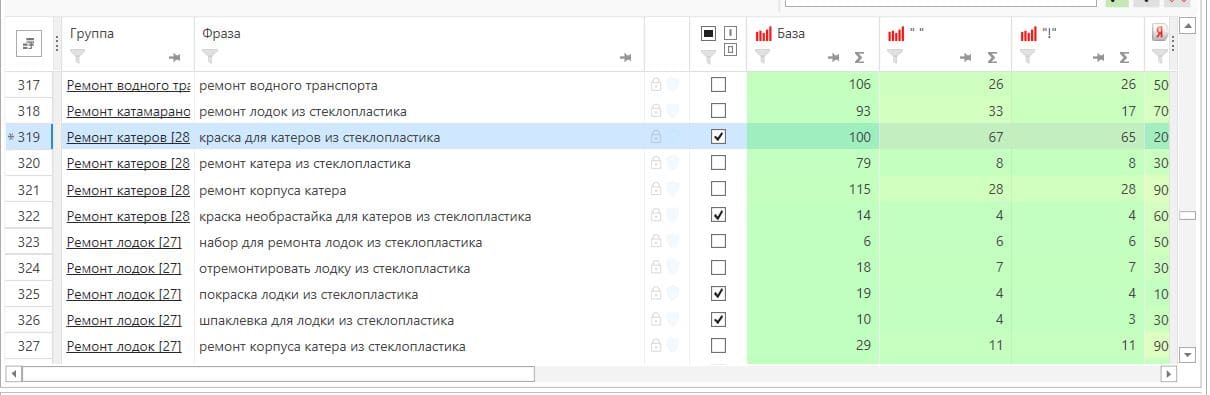
Пример кластера семантического ядра
Что дает составление семантического ядра для бизнеса и зачем используется?
Определение целевой аудитории
Потребители по-разному ищут продукт, семантика определяет все точки контакта с платежеспособной аудиторией. Пример: запрос «Услуги электрика» — это услуги с низким чеком, «электромонтажные работы» предполагает сегмент B2B с высокими чеками.
Контент-план публикаций, основанный на цифрах
Выбранные запросы ядра объединяются в группы и формируют темы для публикаций на сайте с количественным подтверждением популярности (запрашиваемости в поиске). Понятно что писать и для какого потребителя.
Усиление компетенций бизнеса
Семантика позволяет подчеркнуть конкурентные преимущества, выбрать запросы, которые раскрывают экспертность компании на рынке.
Архитектура спроса проекта
При старте проекта выгоднее сразу делать правильный сайт под seo-продвижение и рекламу: проработать структуру ассортимента с позиции спроса и конкурентности поисковых запросов.
Семантическое ядро – это вид маркетингового исследования, которое позволяет определить, как платежеспособная целевая аудитория ищет деятельность компании в сети интернет.
Презентация услуги: от семантики до прототипов страниц (видео без звука)↓
Что входит в готовую семантику? Каждый этап работ — отдельный аналитический продукт ↓
Этап 1. Визуализация сбора в MindMap-карте и конкурентный анализ
Прежде чем детально погружаться в сбор запросов, согласовывается черновая карта тематики из базовых запросов для гарантии полноты сегментов. Предварительно оцениваются сильные конкуренты и их семантика. Это позволяет синхронизировать понимание тематики и добавить специальные термины (которые может знать только специалист, представитель заказчика). В процессе сбора карта видоизменяется и дополняется в соответствии с глубиной исследования.

Дополнительные примеры
Итоговый продукт — pdf-документ, включающий граф из потенциальных кластеров ключевых слов. Удобен для согласования видения между seo-специалистом и бизнесом (все ли кластеры учтены для начала сбора ядра)
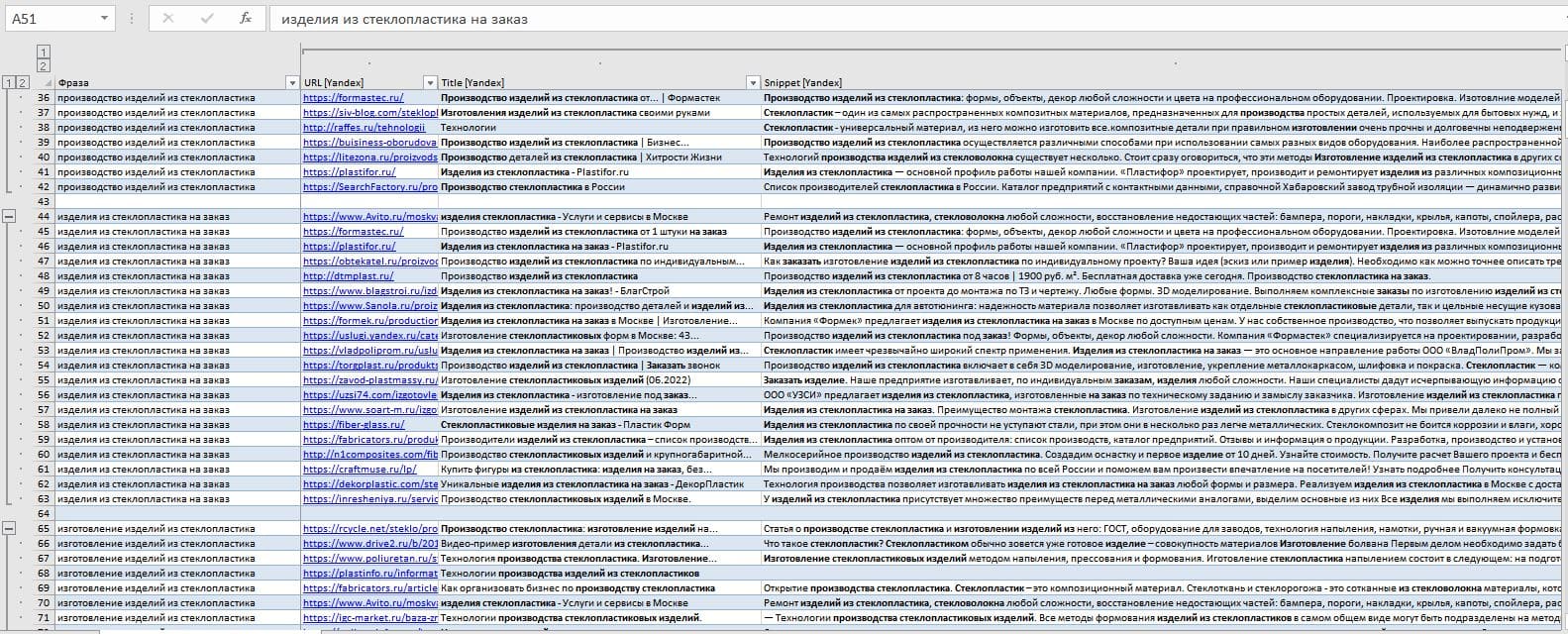
 Итоговый продукт — собранные, очищенные и сгруппированные ключевые слова. Формат представления — MS Excel. Это уже собранные ключевые слова, их можно использовать для внедрения на страницы сайта. Для упрощения работы с ядром — составления контент-плана, определения иерархии и плана публикации страниц составляется развернутая структура сайта. Смотрите следующий этап работ ↓
Итоговый продукт — собранные, очищенные и сгруппированные ключевые слова. Формат представления — MS Excel. Это уже собранные ключевые слова, их можно использовать для внедрения на страницы сайта. Для упрощения работы с ядром — составления контент-плана, определения иерархии и плана публикации страниц составляется развернутая структура сайта. Смотрите следующий этап работ ↓
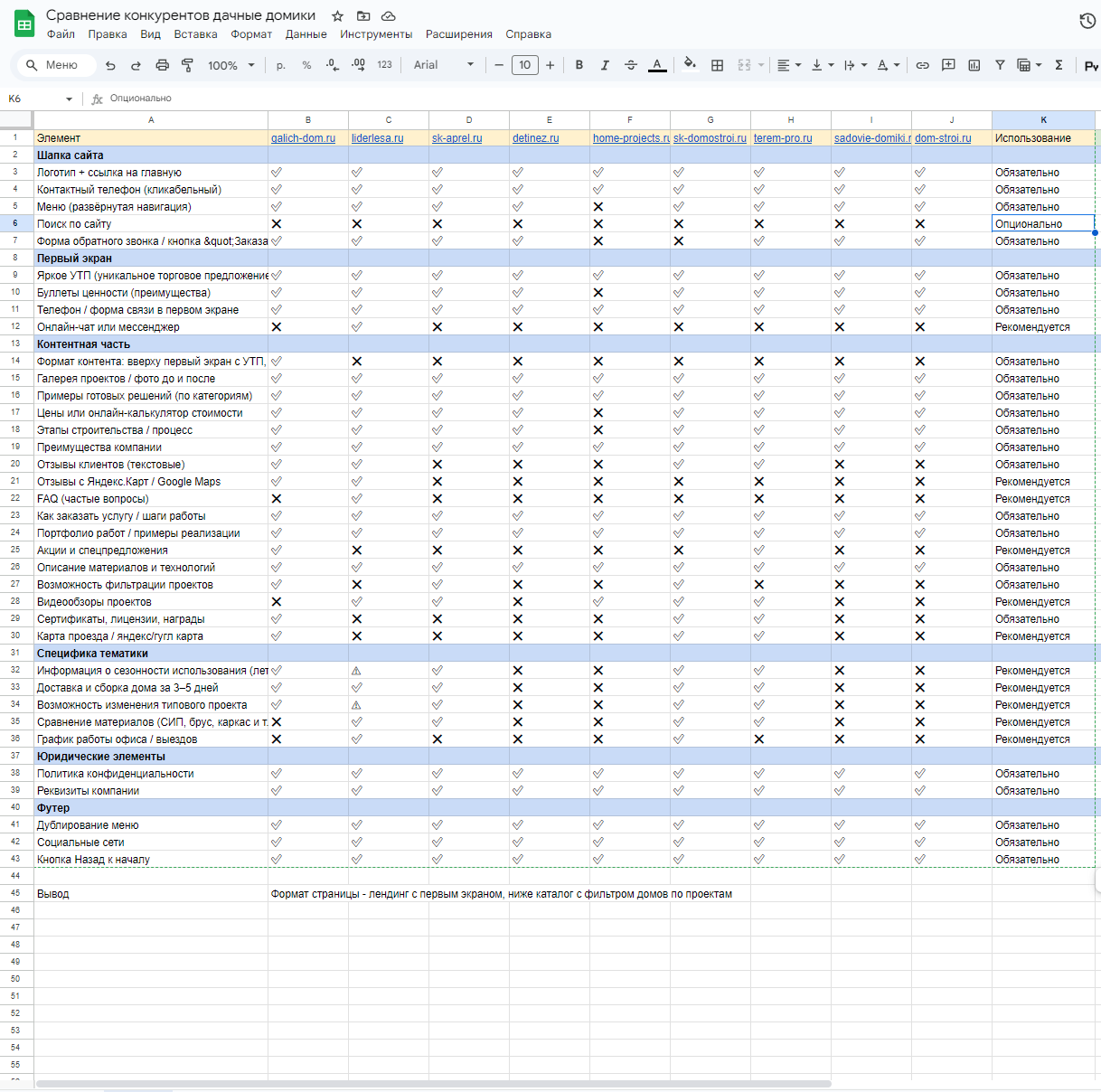
По результатам сбора семантики фиксируются структурные решения и особенности страниц конкурентов.
 Заказчику предлагается отдельный документ с конкурентным анализом и лучшими проектами в тематике. Этот документ позволяет проектировать страницы на уровне и лучше конкурентов, закрывает вопросы выбора структурного решения для каждой отдельной страницы.
Заказчику предлагается отдельный документ с конкурентным анализом и лучшими проектами в тематике. Этот документ позволяет проектировать страницы на уровне и лучше конкурентов, закрывает вопросы выбора структурного решения для каждой отдельной страницы.
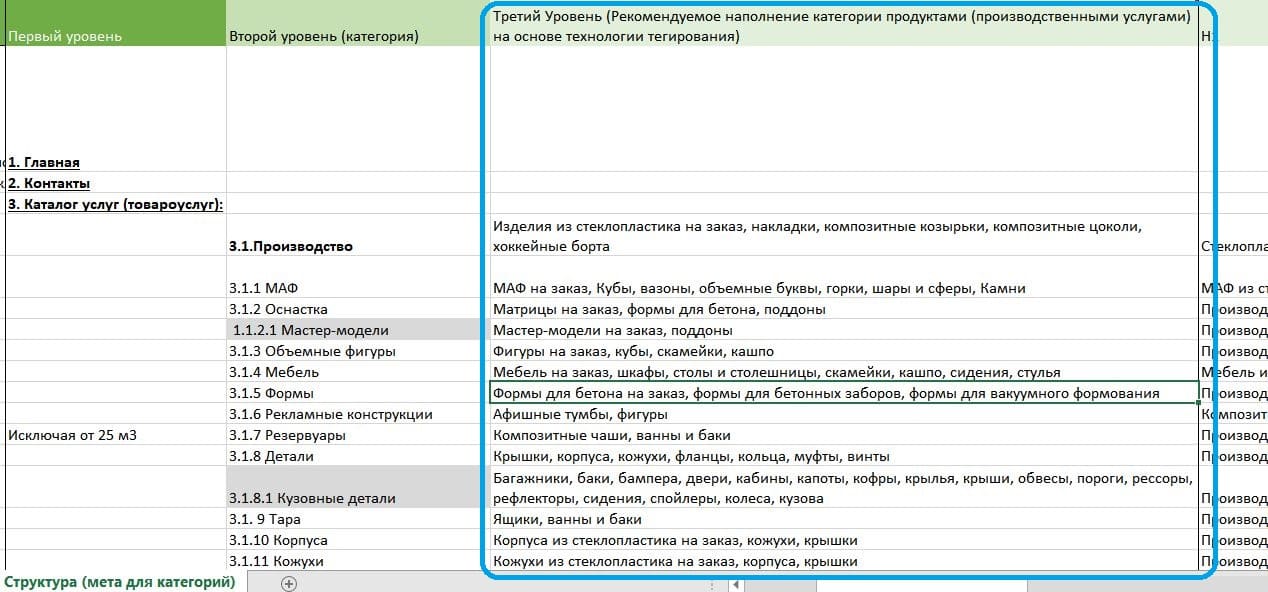
Структура сайта — документ, содержащий все страницы сайта в иерархичном виде. Включает контент-план из названий страниц, очередность публикации (обрабатываем в 1-й, 2-й, 3-й и последующие месяцы работ), базовые элементы seo-оптимизации: заголовок страницы H1, заголовок страницы Title и описание Description для поисковых систем.
 Итоговый продукт — иерархия страниц, базовые теги для seo и приоритет внедрения в виде контент-плана (в какой точно период работ какие именно страницы размещаются). При сдаче заказа проводится развернутая консультация по собранной семантике и продвижению проекта заказчика в целом.
Итоговый продукт — иерархия страниц, базовые теги для seo и приоритет внедрения в виде контент-плана (в какой точно период работ какие именно страницы размещаются). При сдаче заказа проводится развернутая консультация по собранной семантике и продвижению проекта заказчика в целом.
Структура является трудоемким процессом, поскольку каждый элемент семантики переводится в удобный для использования и презентабельный вид. Но, можно еще детальнее. Если нужно увидеть как реально будет выглядеть страница с внедренными ключевыми словами составляется прототип ↓
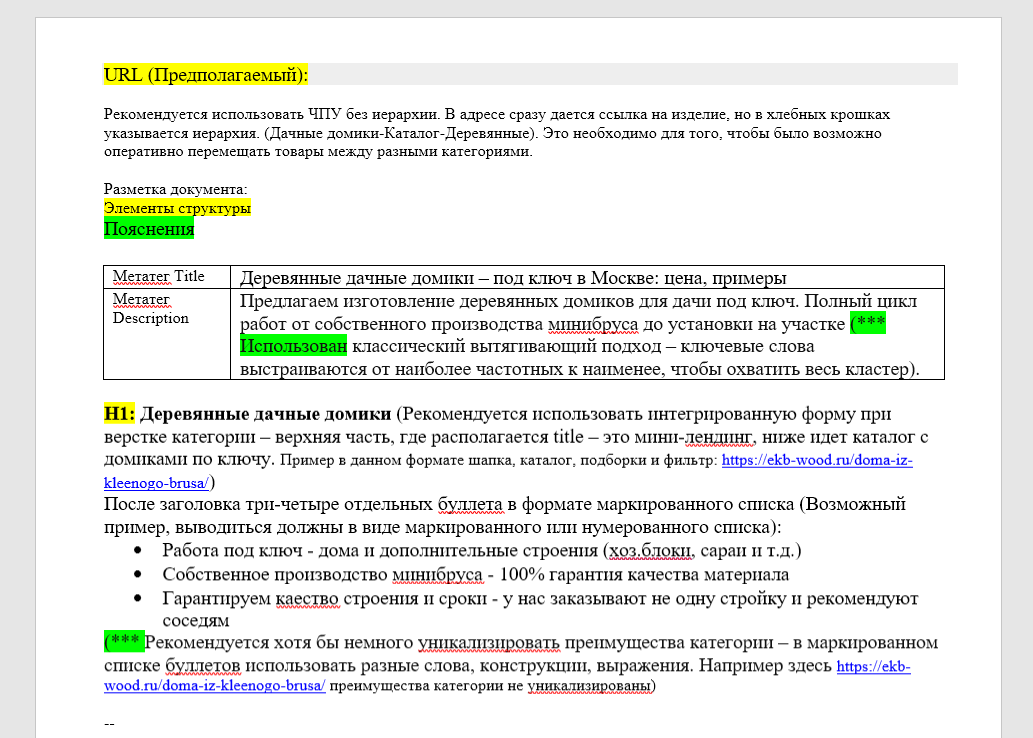
Техническое задание — это документ, описывающий текстовую структуру, полученную из собранных ключевых слов. Для продвижения одинаковых по типу страниц создаются не разные технические задания, а одно мастер-тз, которое размножается на требуемое количество страниц.
Почему создается расширенное техническое задание, учитывающее не просто ключевые слова, а структуру документа? Современное SEO — это объединение сервисных и продуктовых характеристик сайта. Копирайтер, который просто вписывает ключевые слова, не учитывает расположение калькуляторов, квизов, интерактивных элементов и других коммерческих факторов страницы — это делает seo-специалист.
Мы сравниваем существующий или проектируемый сайт с конкурентами по матрице коммерческих факторов и разрабатываем подробное техническое задание для цели: понять как сделать страницу лучше, чем у конкурентов.
Итоговый продукт данного этапа — матрица коммерческих факторов и структура страницы в виде технического задания
В случаях сложной структуры дополнительно разрабатывается прототип страниц. Включает реальное размещение всех элементов структуры семантического ядра на страницах сайта. Задача прототипа — синхронизировать видение заказчика, маркетолога и программиста.
Посмотреть прототип в масштабе онлайн ►
Итоговый продукт — интерактивный прототип (показывает как должен выглядеть фильтр интернет-магазина или какие смыслы нужно включать в тексты для экспертных тематик — образование, медицина, промышленное оборудование).
Аналитическая часть завершена — по техническому заданию и прототипу (если использовался) создаются мастер-страницы (основные страницы сайта для посетителей — например страницы товаров, услуг, карточка магазина и т.д.). Мастер-страницы учитывают все коммерческие факторы документа в рамках его типа. Например, если мы делаем категории для интернет-магазина, то создаем одно мастер-тз, а затем размножаем на требуемое количество страниц-категорий путем изменения текстовых элементов структуры.
В то время пока выполняется техническая сборка сайта, мы переходим к seo-продвижению: делаем технические задания под все страницы семантики, запланированные к внедрению, заказчик наблюдает за тем какие страницы размещаются в отчетном файле со структурой сайта.
Примеры готовых страниц (семантика, структура. смыслы и текст — convertbiz; верстка и выкладка страницы — заказчик)
🔍 Дачные домики (открыть в новой вкладке)
(коммерческие запросы)
🔍 Техническая поддержка серверов (открыть в новой вкладке)
(коммерческие запросы)
Современное SEO — это аккуратное внедрение ключевых слов в элементы страницы (калькуляторы, интерактивные блоки, списки и т.д.). Мы делаем такие страницы, пишем для них структуру, тексты и передаем заказчику для размещения.
Важно!
Основа качественного ядра — это аналитические этапы процесса: конкурентный анализ и оценка структурных решений сайтов-конкурентов в выдаче. Просто собрать ключевые слова, выдернув их из вордстата или другого сервиса можно за 30 минут. Только смысла в таком ядре нет, внедрять его бесполезно — это сырые данные, не пригодные для использования.
Онлайн-калькулятор для оценки работ по SEO-оптимизации: от ядра до результата
Ответьте на 6 простых вопросов, ознакомьтесь с подробными примерами по ходу квиза и получите расчет онлайн сразу
Современное поисковое продвижение основано на интерфейсном внедрении ключевых слов. Поисковые запросы включаются в элементы страницы: каталоги, фильтры, меню, теги, элементы дизайна
Создавать страницу проще, глядя на готовый прототип, а не ключевые слова
Прототип более трудоемок в исполнении, но сразу позволяет увидеть реальный вид страницы со всеми особенностями интерфейса. Точная стоимость прототипирования определяется после сбора семантического ядра (мы изучаем целевую аудиторию, собираем ядро, проектируем структуру сайта и определяем стоимость проектирования интерфейса под ядро — прототипа)
- Семантическое ядро
-
- Технические задания
-
- Прототипы страниц
-
Современное поисковое продвижение основано на интерфейсном внедрении ключевых слов. Поисковые запросы включаются в элементы страницы: каталоги, фильтры, меню, теги, элементы дизайна
Создавать страницу проще, глядя на готовый прототип, а не ключевые слова
Прототип более трудоемок в исполнении, но сразу позволяет увидеть реальный вид страницы со всеми особенностями интерфейса. Точная стоимость прототипирования определяется после сбора семантического ядра (мы изучаем целевую аудиторию, собираем ядро, проектируем структуру сайта и определяем стоимость проектирования интерфейса под ядро — прототипа)
Пример: почему важна ручная смысловая проверка запросов?
Сбор всех ценных фраз
При сборе важно получить максимум ключевых слов, которые использует клиент для поиска продукта. Например, есть три запроса:

- (1) панели из стеклопластика
- (2) кожухи из стеклопластика
- (3) корпуса из стеклопластика
По технологическому процессу для предприятия-изготовителя — это одинаковые изделия. Для клиента — они все разные и для поисковой системы они все разные.
(1) коммерческий, его ищут больше B2C-сегмент (панель для грузового автомобиля), меньше B2B. (2) и (3) тоже коммерческие, ищут больше B2B-сегмент (корпуса устройств или кожухи для флотационного оборудования)
Причем, при кластеризации запросы (1), (2) и (3) должны находиться на разных страницах, так как описывают разную целевую аудиторию. Важно не смешивать разные по намерению пользователя запросы между собой, чтобы обращаться к нужной бизнесу целевой аудитории.
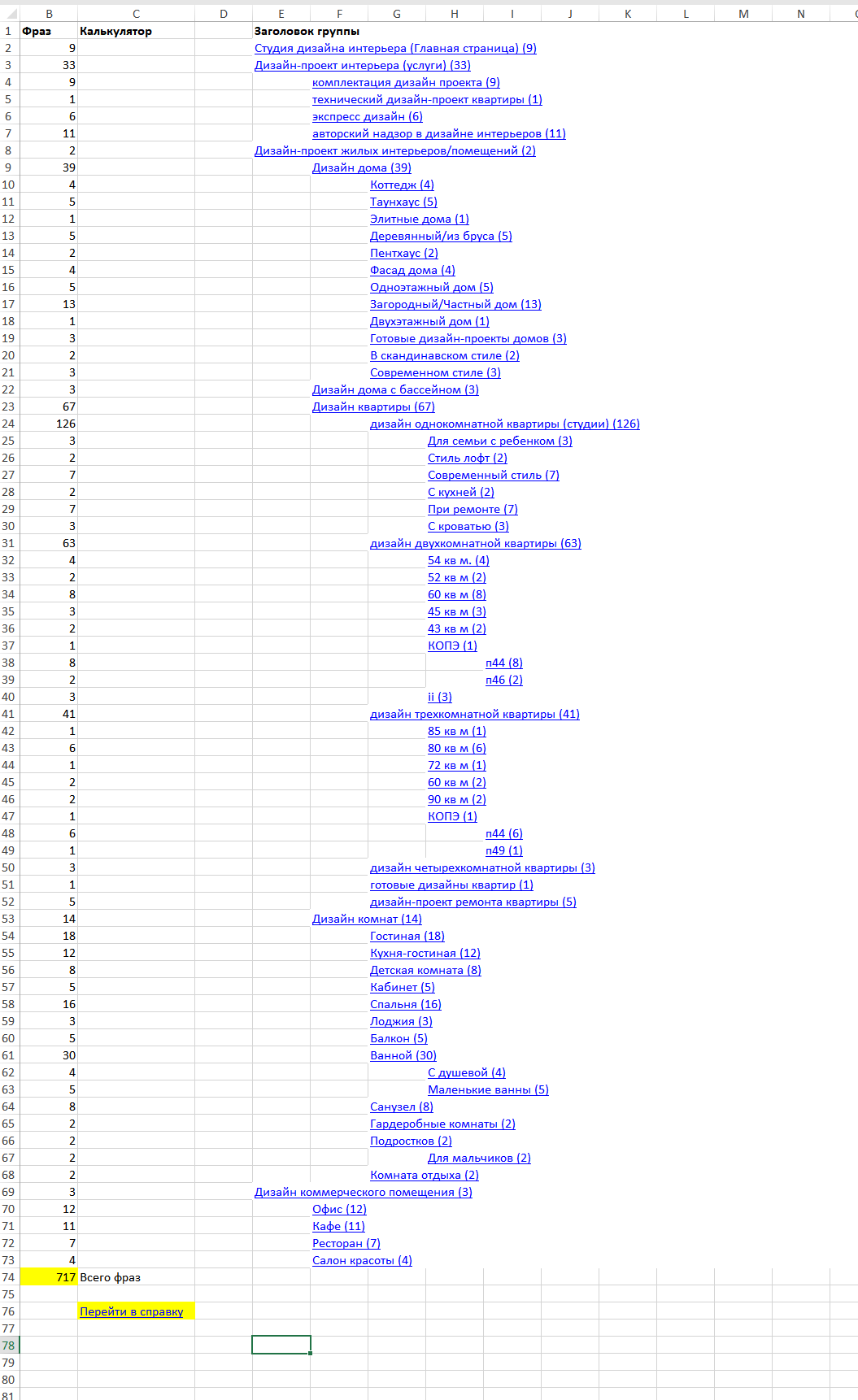
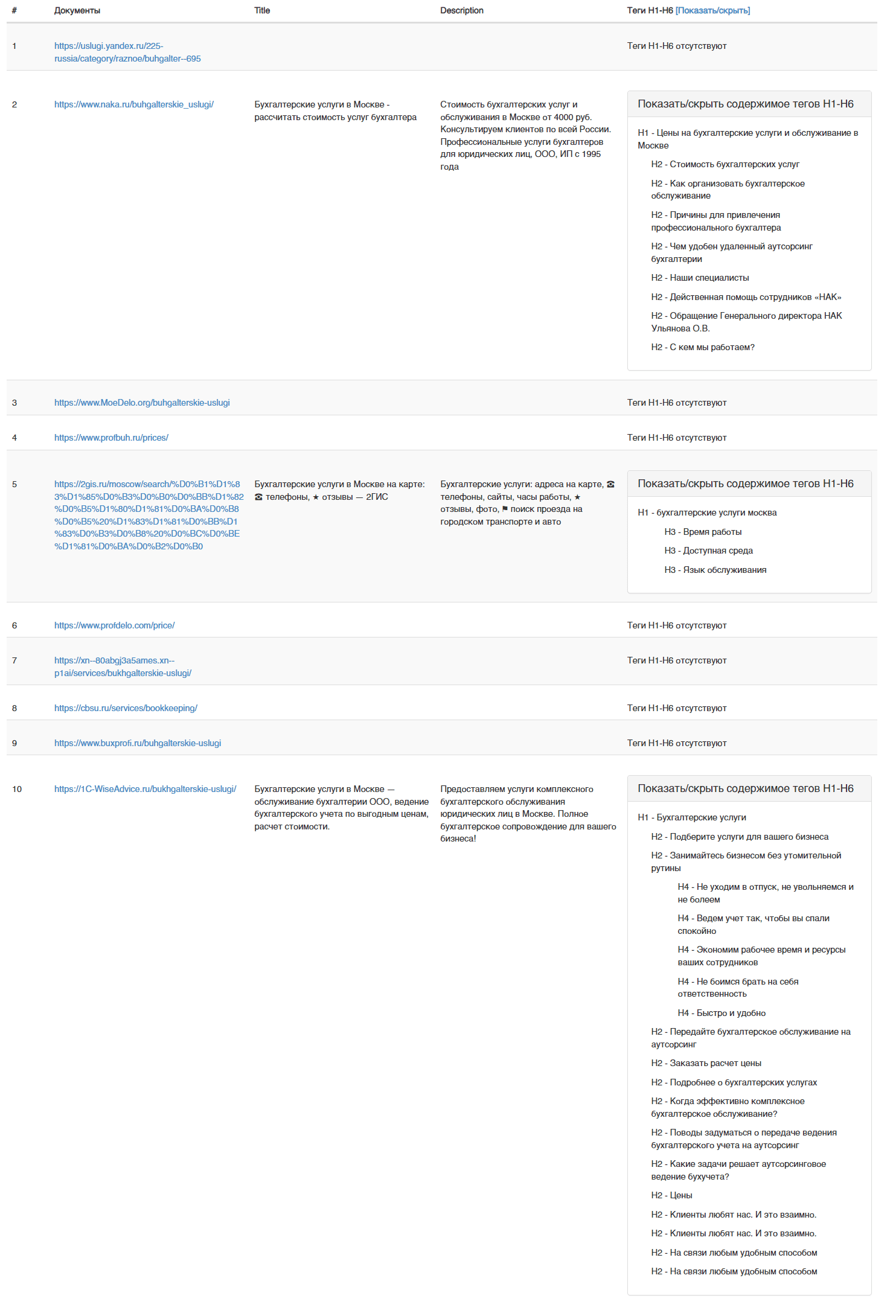
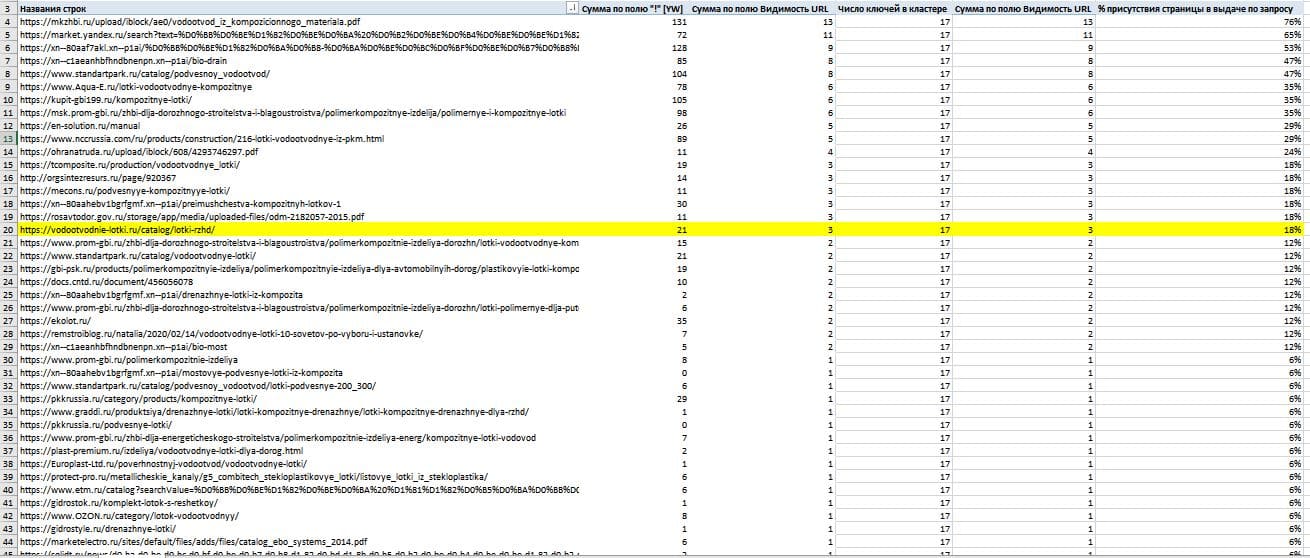
Готовый пример семантического ядра для SEO-проектирования интернет-сайта с нуля
Как выглядит семантическое ядро смотрите по ссылке. Включает ручную кластеризацию по топу выдачи поисковой системы с частотностью, а также прогнозные значения конкуренции (на титульной странице со структурой представлена подробная справка).
Файл рекомендуется скачать на компьютер для просмотра в MS Excel или подобной программе
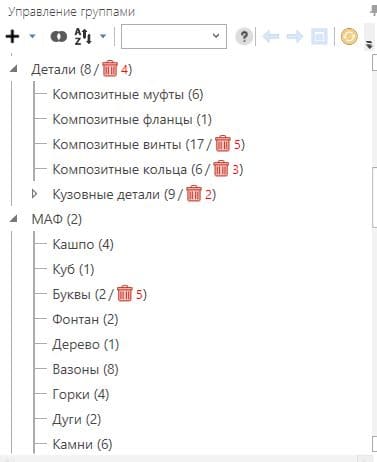
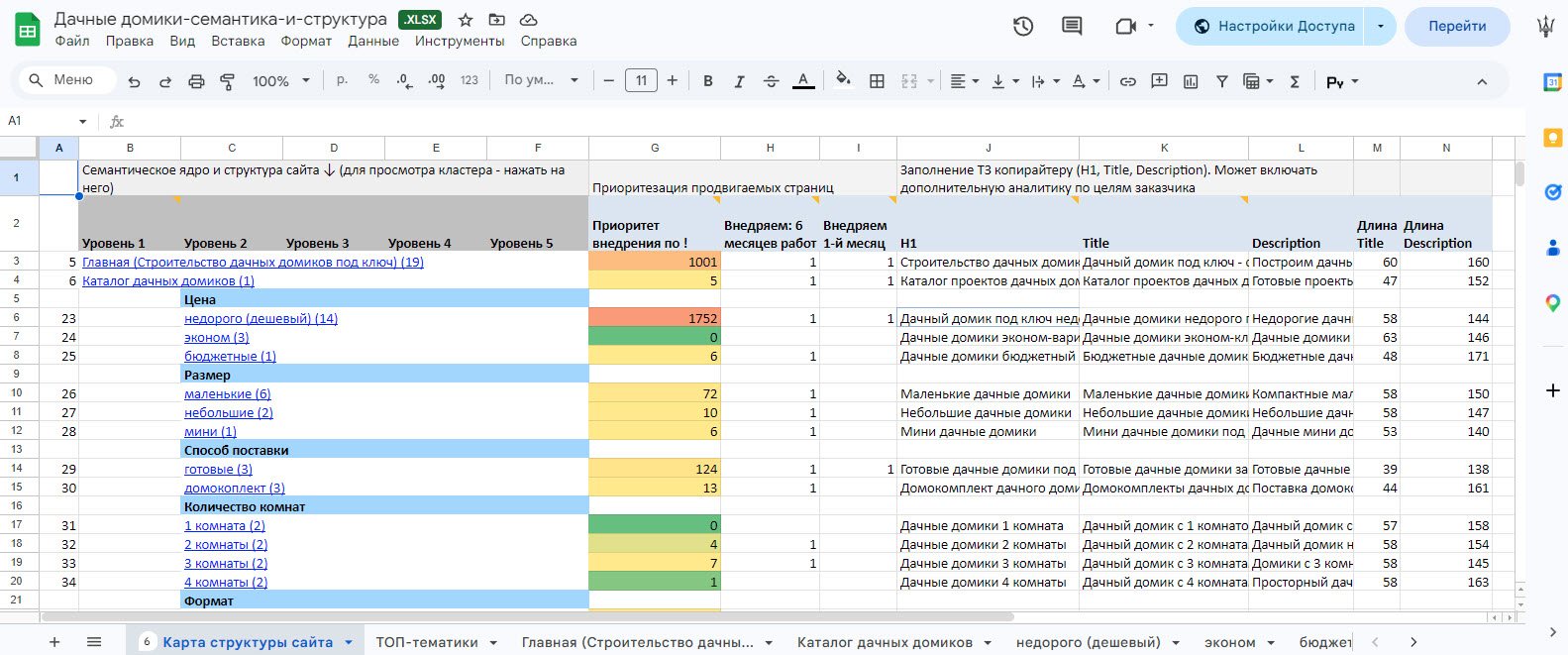 Пример структуры кластеров семантического ядра
Пример структуры кластеров семантического ядра
Особенности подхода:
- Современная статистика Вордстат и других источников не отображает все запросы. Методика учитывает точную частотность, прогнозируется пессимистичный сценарий роста.
- На практике, оптимизированная страница собирает больше трафика, поскольку начинает ранжироваться по низкочастотным и микро низкочастотным запросам.
Например, клиента может дать фраза «изготовление объемных конструкций из стеклопластика методом матричного формования». Запрос из 8 слов, в статистике и в семантике его нет, но запрос был набран в поисковой выдаче и дал звонок клиента.
Такой эффект достигается за счет использования сторонних источников семантики и текстового анализа (заголовки структуры, вхождения текстового и интерфейсного вида и другие факторы) проектируемой страницы. Фактически, страница с высоким уровнем релевантности ранжируется по дополнительным вхождениям, которые отчасти формирует пользователь.

Частный специалист по семантике
Семантическое ядро – это комплексное исследование рынка с позиции интернет-маркетинга. Ответ на вопрос как потенциальные клиенты ищут Ваш бизнес и база для стратегии продвижения.
Преимущества работы:
- Маркетинговый подход – объясняем каждое действие в понятных бизнесу терминах («этот» кластер ключей важен, так как приносит больше выручки). Заказчик получает инструкцию по использованию ядра и консультации при необходимости (в мессенджерах, теелфон, вк).
- Итерационность – собирая семантику, мы изучаем деятельность, конкурентов; уточняем особенности, правим список запросов в несколько этапов, соотносим ядро с реальными потребностями бизнеса.
- Уникальность – создается список запросов, учитывающий максимум возможных точек контакта с потребителем и применимых именно в вашем бизнесе.
Семантика требует понимания бизнеса заказчика. Мы много общаемся с заказчиком и задаем разные вопросы, но выдаем качественный продукт. Подписывайтесь на экспертный блог вконтакте.
Кейсы быстрой семантики: расширяем входящий спрос
В маркетинговой постановке семантика расширяет и углубляет смыслы бизнеса. Не просто парсинг и сбор ключевых запросов — управление смыслами и входящим спросом через ключевые слова. Каждая группа — отдельная ниша в сегменте бизнеса, для которого создается страница и разрабатывается способ коммуникации.
Ниже представлены примеры быстрого сбора и ручной кластеризации для понимания, какие сегменты еще нужно добавить в действующий сайт.
Коммерция: услуги бухгалтера
Основной запрос бухгалтерские услуги детализирован на 54 группы и 1061 запрос (коммерческие и информационные). Только коммерция — 783 ключевых слова
Коммерция: композитное производство
Основной запрос, характеризующий нишу бизнеса: изготовление изделий из стеклопластика на заказ детализирован на 139 групп и 1338 коммерческих запросов
Коммерция: производство видео
Основной запрос «производство видео на заказ». Получено 81 единица широких групп, 694 ключевого слова
Инфо: подарки
Информационная ниша, запросы под статьи для Яндекс.Дзен. 398 широких групп, 4011 ключевых слов. Без структуры. Цель — выбрать максимум запросов для полуавтоматического написания статей по шаблону.
Коммерция: услуги дизайна
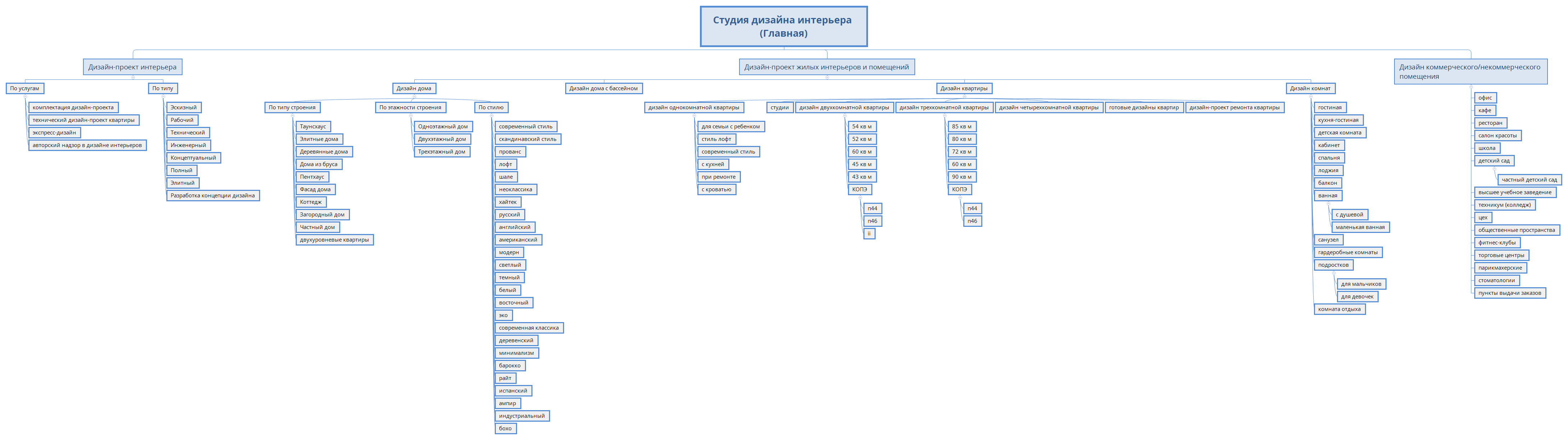
Основные запросы Дизайн квартир и Студия Дизайна детализированы на 170 групп и 717 фраз
Результаты применения качественного ядра для маркетинговой деятельности:
Поисковое SEO-продвижение
- больше страниц под запросы, которые используют клиенты
- подробный контент-план (что ищут клиенты, под что делать страницы)
- исследование коммерческих факторов (какие элементы размещать на страницах)
- проектирование (какая структура страниц должна быть у сайта/блога/аккаунта)
Маркетинг в целом
- Определение конкуренции (в чем экспертиза конкурентов выше)
- Целостное понимание спроса (что еще ищут и можем ли это делать)
- Модель всего спроса в тематике (понимание, куда развивается спрос)
- Комплексный обзор тематики (а что еще ищут и подходит ли это бизнесу)
Контекстная реклама в Яндекс.Директ
- Количество и качество сегментов для старта (какие страницы размещать первыми)
- Медиаплан (сколько кликов даст каждый сегмент)
- Какие запросы собирать не нужно (больше клиентов с высокими чеками)
- Идеи для расширения и большей специализации спроса
Найдем еще 10-300+ точек входа клиентов в вашей деятельности через ключевые слова?
Написать в Telegram @mrcbiz и получить примеры продающей семантики
Семантическое проектирование — инструмент для понимания спроса
Работаем со всеми видами проектов
- Корпоративные сайты товаров и услуг, лендинги и порталы
- Интернет-магазины, маркетплейсы и агрегаторы
- Информационные сайты, блоги, ленты новостей
- Youtube-каналы, блоги на Яндекс.Видео, новостные сайты и проекты
- Семантика под доски объявлений (Авито, Юла)
Ключевые услуги
- Сбор семантического ядра под ключ
- Кластеризация по выдаче с ручной проверкой запросов
- SEO-проектирование вновь создаваемого проекта
- Разработка структуры сайта
- Формирование технических заданий копирайтеру на страницы
- Чистка и кластеризация ранее собранного ядра
- Создание интерактивных прототипов под сложные интерфейсы
- Досбор и расширение ядра для уже существующего проекта
- Сбор запросов у конкурентов
- Консультации по внедрению семантики на сайт
Типы ядер
- Для нового сайта (проектируем с нуля)
- Дополнение ядра для старого сайта с трафиком
- Для вновь создаваемых разделов и категорий (расширение разделов)
- Большие ядра под отдельную страну
- Маленькие и средние по объему для региональных проектов
Производство
Металлоконструкции
Композитные материалы
Сварочные работы
Мероприятия по гражданской обороне
Сантехнические работы для промышленности
Бады
Геодезические работы
Товары почтой
Сложные услуги
Бухгалтерский учет
Дизайн интерьера
Внедрение 1с
Видепродакшн
Местный региональный бизнес
Разработка ботов в Телеграме
Технологическое присоединение к электросетям
Проектирование инженерных систем
Домашний сервис
Электрик
Сантехник
Мастер на час
Интернет-магазины с товарами CBD
Стоматология
Системное администрирование
IT-поддержка
Лицензионный гемблинг и ставки на спорт
- Решаемые задачи
-
Работаем со всеми видами проектов
- Корпоративные сайты товаров и услуг, лендинги и порталы
- Интернет-магазины, маркетплейсы и агрегаторы
- Информационные сайты, блоги, ленты новостей
- Youtube-каналы, блоги на Яндекс.Видео, новостные сайты и проекты
- Семантика под доски объявлений (Авито, Юла)
Ключевые услуги
- Сбор семантического ядра под ключ
- Кластеризация по выдаче с ручной проверкой запросов
- SEO-проектирование вновь создаваемого проекта
- Разработка структуры сайта
- Формирование технических заданий копирайтеру на страницы
- Чистка и кластеризация ранее собранного ядра
- Создание интерактивных прототипов под сложные интерфейсы
- Досбор и расширение ядра для уже существующего проекта
- Сбор запросов у конкурентов
- Консультации по внедрению семантики на сайт
Типы ядер
- Для нового сайта (проектируем с нуля)
- Дополнение ядра для старого сайта с трафиком
- Для вновь создаваемых разделов и категорий (расширение разделов)
- Большие ядра под отдельную страну
- Маленькие и средние по объему для региональных проектов
- Опыт в тематиках
-
Производство
Металлоконструкции
Композитные материалы
Сварочные работы
Мероприятия по гражданской обороне
Сантехнические работы для промышленности
Бады
Геодезические работы
Товары почтой
Сложные услуги
Бухгалтерский учет
Дизайн интерьера
Внедрение 1с
Видепродакшн
Местный региональный бизнес
Разработка ботов в Телеграме
Технологическое присоединение к электросетям
Проектирование инженерных систем
Домашний сервис
Электрик
Сантехник
Мастер на час
Интернет-магазины с товарами CBD
Стоматология
Системное администрирование
IT-поддержка
Лицензионный гемблинг и ставки на спорт
Комплексное внедрение: ТЗ копирайтеру под ключ
Наш ключевой продукт в семантике – это технические задания на создание страниц. Поисковое продвижение – сложная услуга, требует взаимодействия разных специалистов (как минимум seo-специалиста и представителя клиента). Комплекс из SEO-аналитики и конкурентного анализа в виде расширенных тз-шек позволяет сделать этот процесс простым и результативным.
При заказе ТЗ клиент получает:
Комплекс услуг по SEO-оптимизации в виде плана для одной страницы
- Семантическое ядро и LSI-фразы
- Детальную структуру страницы с внедрением ключевым фраз
- Заполненные технические данные (Мета-теги, рекомендации по сервисному наполнению страницы и т.д. Подробнее смотрите здесь)
Внутренний контроль процесса со стороны организации-клиента.
Заказчик получает детальный план по оптимизации:
- создает контент и размещает на странице своего сайта под контролем студии Конверт;
- все данные от сайта остаются у заказчика (исключаются согласования по получению доступа);
- организация-заказчик получает подробные рекомендации по улучшению страниц сайта, также в виде технических заданий.
Упрощение взаимодействия с копирайтерами
Делегирование процессов взаимодействия с копирайтерами (поиск, отбор, проверка компетенций в теме, размещение заданий, проверка готовой работы, отправка на доработку, решение спорных вопросов и т.д. — кто хоть раз заказывал контент, тот осведомлен о этих моментах).
Тарифы и основные услуги в области семантического проектирования страниц
Ядро и структура сайта от 30000 р
- Все элементы семантического ядра
- Исследование структуры конкурентов на основе SERP (выдачи поисковых систем)
- Составление аналитической записки по особенностям структуры (преобладающий формат контента, особенности коммерческих факторов и интента пользователей, структура основных страниц)
- Разработка структуры сайта
- Распределение ключевых слов по структуре сайта
- Разработка мета-тегов для категорий (Title, Description)
- Оценка стоимости внедрения семантики (количество статей, стоимость написания и размещения)
Объем услуги: 500 ключевых слов + подробная структура проектируемого ресурса
Сбор семантики по приоритетным направлениям заказчика, комплексное исследование тематики и формирование оптимальной структуры сайта
Техническое задание на контент: от 3000 р
- Текстовый анализ конкурентов по тематике страницы (общий вид страниц, особенности структуры, требования к наличию сервисных элементов — калькуляторы, интерактивные элементы и т.д.)
- Составление семантического ядра с учетом LSI-выражений на основе точечной аналитики (для основных ключей количество вхождений определяется в точном численном виде)
- Определение оптимального объема статьи с учетом общего количества знаков
- Разработка структуры страницы — определение заголовков, подзаголовков и учет нюансов тематики (подсказки копирайтеру при написании текста)
- Составление метатегов Title, Description, H1 с учетом максимального охвата тематики (читабельные, кликабельные, оптимальные по длине и вхождениям ключей без переспама)
- Сбор источников для копирайтера/автора контента (при необходимости с указаниями, какие элементы источника рекомендуется интегрировать в описываемый пункт структуры)
Объем услуги: ТЗ на 1 статью
Выполнение комплекса работ по поисковой оптимизации для 1 страницы сайта под ключ
Дополнительные услуги
- Автоматическая кластеризация. Создание групп ключевых слов на основе программы Keyassort и онлайн-сервисов. Подходит для инфо-статей и материалов, где не требуется глубокий текстовый анализ.
- Ручная кластеризация. Наивысшая глубина проработки, текстовый анализ и трехэтапная проверка. Собранные группы проверяются вручную, каждая фраза гарантированно находится в своем кластере.
Как выглядит результативная семантика: особенности прогнозирования трафика
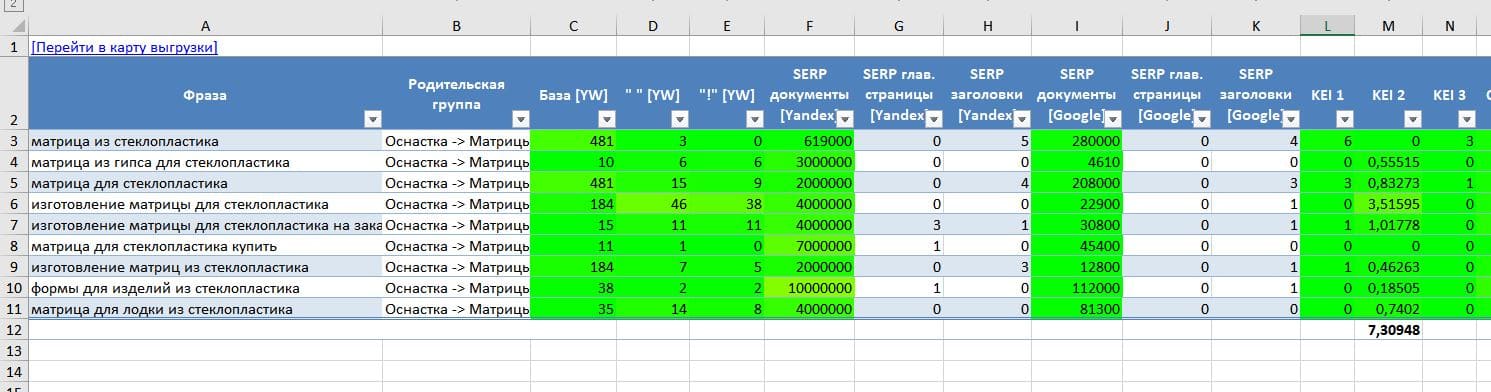
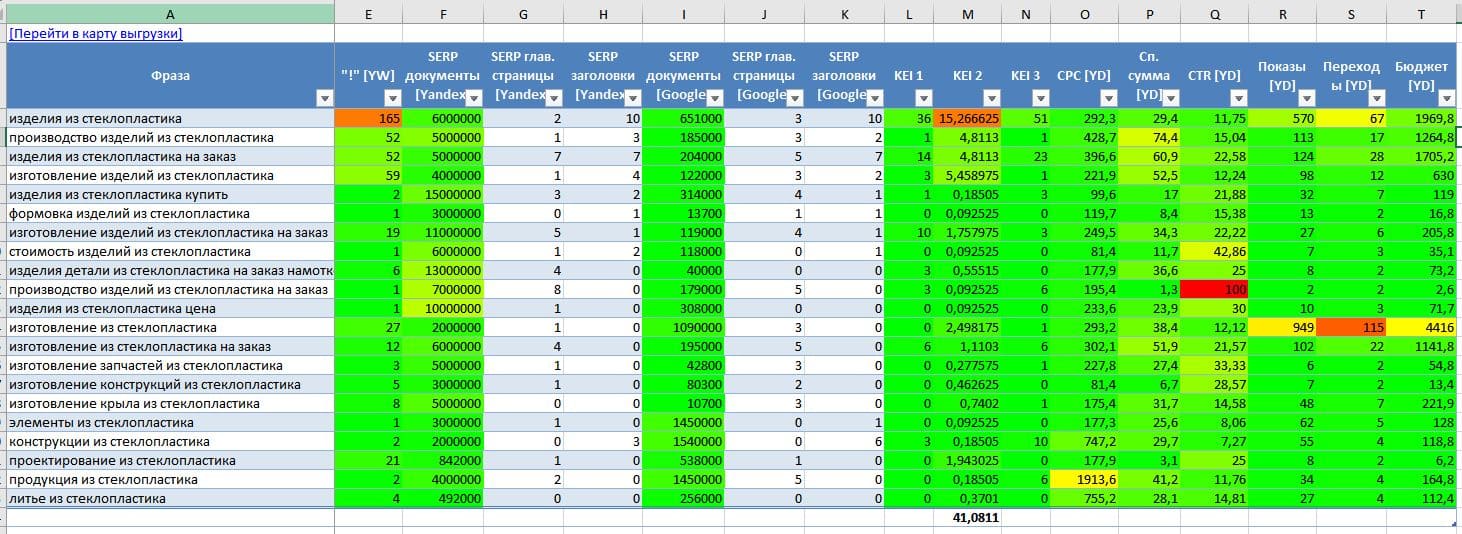
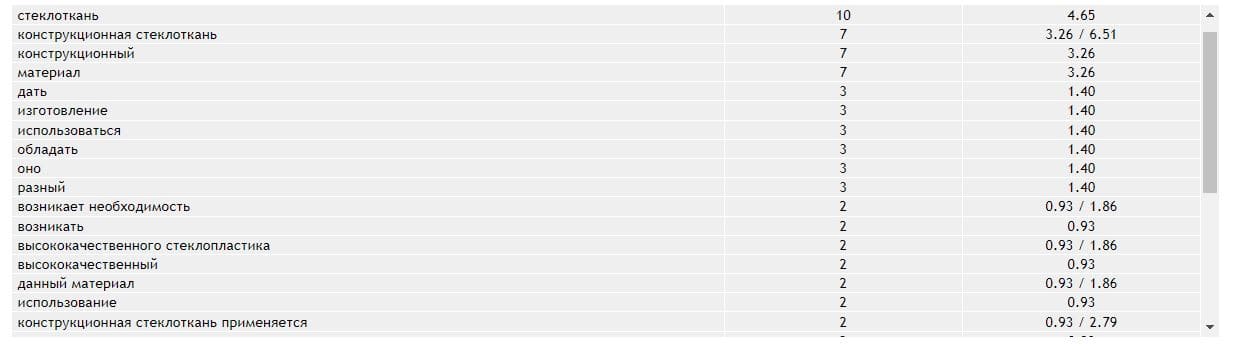
Итоговое семантическое ядро формируется в виде таблицы MS Excel и включает следующие элементы:
- Название запросной группы (кластера) – это укрупненное наименование товара/услуги, которую ищет потребитель.
- Запросы – это ключевые фразы, которые описывают потребность целевой аудитории. Запросы, соответствующие группе, располагаются на одной странице сайта.
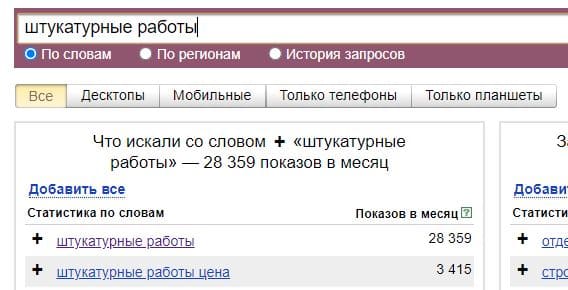
- Частотность запросов – это количественная оценка обращений целевой аудитории по отдельной фразе. Позволяет понять, сколько раз в месяц потребитель набирает запрос в поисковую выдачу.
Частотность оценивается в трех категориях:
| Тип частотности | Общая: услуги бухгалтера | Фразовая: «услуги бухгалтера» | Точная: «!услуги !бухгалтера» |
| Свойство | Включает запросы, содержащие избранную фразу. Например, сюда относятся показы с учетом различных расширений запросов. | Включает запросы, содержащие только указанную фразу с учетом различных словоформ. | Фиксирует словоформу запроса. |
| Пример | Услуги бухгалтера включает: услуги главного бухгалтера, услуги бухгалтера для ип, услуги бухгалтера для ооо | «услуги бухгалтера», «услуги бухгалтеров» и т.д. | Статистика только по фразе «услуги бухгалтера» |
- Прогноз посещаемости – это произведение точной частоты запроса на показатели CTR в выдаче. Статистика показывает, что среднее CTR из выдачи по топ 1-5 колеблется от 21 % до 1%.
Для менеджмента важно получать прогноз трафика продвигаемой страницы, по этой причине мы предоставляем минимальный объем трафика, который наберет страница (помня о влиянии таких факторов как непостоянность позиций, персонализированность выдачи, Яндекс.Бандит для новых сайтов, поведенческие факторы и т.д.)
Учитывая вероятностный характер позиций — мы рекомендуем внедрять максимально возможное количество страниц без каннибализации (конкуренции страниц между собой). Особенно это актуально в промышленных тематиках, где 1 звонок может принести несколько миллионов рублей продажами.
Разница в прогнозах второго примера достигнута за счет подтягивания дополнительных запросов и высокой позиции по выдаче Российской Федерации в поисковой системе Google (а также того факта, что на момент продвижения контекстной рекламы в Гугле по этому запросу не было).
Особенности кластеризации ключевых слов
Кластеризация – это разбиение ключевых слов на группы (кластеры) по входящему интенту (намерению), схожести поисковой выдачи и интересам пользователей поисковых систем. Кластеризация в интернет-маркетинге является адаптацией метода статистического анализа и является важной по следующим причинам:
1) Позволяет определить правильную структуру страницы.
Пример 1: «купить гидроцикл Yamaha» и «купить гидроцикл Yamaha GP 1800».
Запросы схожие, но интенты – намерения пользователя, разные. В первом случае пользователь ищет общую категорию гидроциклов, во втором конкретный товар.
Соответственно:
- Для продвижения первого запроса компания должна представить категорию товаров (много гидроциклов бренда Yamaha)
- Для продвижения второго запроса компания должна представить карточку товара гидроцикла Yamaha GP 1800
Продвижение карточки товара по интенту, где в поиске присутствуют только категории – это уничтожение маркетингового бюджета.
2) Позволяет выбрать запросы, которые однозначно образуют единый кластер и соответствующую посадочную страницу.
Страница продвигается не по отдельным ключевым словам, а группам запросов, которые идеально дополняют друг друга и отвечают на запрос пользователя.
Пример 2: есть два кластера запросов «услуги электрика», «услуги электрика москва», «услуги электрика на дом» и «электромонтажные работы», «производство электромонтажных работ», «стоимость электромонтажных работ».
Кластер запросов «услуги электрика» должен располагаться на одной странице (потребители – частные лица». Кластер запросов «электромонтажные работы…» должен располагаться на другой странице (потребители – организации: заводы, магазины, мастерские и т.д. при прочих равных условиях).
Пример 3: есть две группы запросов: 1 — «стеклопластиковая арматура 10 мм», «стеклопластиковая арматура 8 мм», и 2 — «Стеклопластиковая арматура в Москве», «Изготовление стеклопластиковой арматуры».
Должны ли эти запросы продвигаться на одной странице? Ведь логично сделать на сайте страницу «Стеклопластиковая арматура в Москве…» и там продвигать эти запросы?
Оба эти запроса – карточки товара (услуги), если их поместить на страницу «Стеклопластиковая арматура в Москве…» это усилит семантическую целостность страницы, но страница будет расти прежде всего по запросу «Стеклопластиковая арматура…». Этот пример иллюстрирует, что для запроса «Стеклопластиковая арматура в Москве» первая группа образует страницу, вторая обозначает ее тематику (является LSI или маркером, который отражает содержание страницы).
По этой причине логично создать отдельные страницы по каждому из наименований арматуры (потребитель ищет и получает товар строго определенной марки), не забывая при этом про приоритетный и наиболее частотный основной кластер.
3) Позволяет определять приоритеты. Даже самая конкурентная выдача неравномерна – существуют кластеры-ниши, которые являются менее конкурентными, чем все остальные. Кластеризация дает возможность выявлять такие ниши и быстрее получать результат от поисковой оптимизации текстовых факторов страницы.
4) Дает возможность создать удобную и понятную для пользователя страницу. Смысл продвижения в поиске, контекстной рекламе или методами таргетинга – предоставить ответ на вопрос пользователя. Если пользователь получает ответ – он покупает (пусть даже и не сразу) или делает другое ценное целевое действие, которое впоследствии приведет к покупке.
Назначение и функции: отличия в сборе для нового и существующего проекта
Проектирование страницы осуществляется в соответствии с последними трендами оптимизации:
- Актуальный анализ конкурентов;
- исследование особенностей интента пользователей в тематике;
- аналитика, сбор ядра, разработка структуры, создание тз-шек и контента
Сбор с нуля позволяет сделать идеальную структуру, соответствующую методике семантического проектирования страниц
Проблема существующий сайтов заключается в адаптации к изменениям. Старая структура уже имеет трафик (часто значительный) и основная задача не навредить. В этом случае выполняется:
Выгрузка всей существующей семантики;
- текстовый анализ существующих кластеров (соответствуют ли страницы современным требованиям топа);
- исследование упущенных кластеров (сбор ся и внедрение новых страниц);
- разработка проекта исправлений для существующих и новых кластеров (технические, текстовые, структурные и т.д.).
- Новый сайт
-
Проектирование страницы осуществляется в соответствии с последними трендами оптимизации:
- Актуальный анализ конкурентов;
- исследование особенностей интента пользователей в тематике;
- аналитика, сбор ядра, разработка структуры, создание тз-шек и контента
Сбор с нуля позволяет сделать идеальную структуру, соответствующую методике семантического проектирования страниц
- Существующий сайт
-
Проблема существующий сайтов заключается в адаптации к изменениям. Старая структура уже имеет трафик (часто значительный) и основная задача не навредить. В этом случае выполняется:
Выгрузка всей существующей семантики;
- текстовый анализ существующих кластеров (соответствуют ли страницы современным требованиям топа);
- исследование упущенных кластеров (сбор ся и внедрение новых страниц);
- разработка проекта исправлений для существующих и новых кластеров (технические, текстовые, структурные и т.д.).
Отправить заявку на составление семантического ядра
Контакты
Если нужен созвон — после предварительной договоренности в мессенджерах или почте. В условиях обилия спама, заявки на услуги/консультации принимаются в ВК/Макс/TG
Больше полезных материалов в группе ВК
FAQ: Вопросы и ответы по семантическому проектированию
Качественное техническое задание. Постарайтесь заполнить бриф на ядро наиболее подробно, указать ключевые направления бизнеса и варианты запросов, которые описывают целевую аудиторию. Чем точнее заполнено техническое задание, тем больше дополнительных кластеров будет собрано. Какую информацию следует обязательно предоставить:
- Регион деятельности – регионы, города, страны (Пример: г. Челябинск, г. Москва, вся Россия)
- Список ключевых запросов, которые характеризуют бизнес (Пример: услуги сантехника). Основа семантического ядра. В этой графе стоит указать ключевые запросы, на которые стоит обязательно обращать внимание и делать упор в сборе.
- Стоп-слова – список ключевых запросов, которые нельзя брать при сборе
- Продвигаемый сайт (если он есть)
- Перечень прямых конкурентов – 3-5 единиц (можно больше). Если это возможно, стоит указывать какие разделы конкурентов представляют интерес для вашего бизнеса
Записывайтесь на созвон в Skype, Ms Teams, Zoom или мессенджерах. Заполним бриф вместе с Вами в процессе консультации.
Заключается договор о оказании услуг, заказчик вносит предоплату в размере 5000 рублей за 500 ключевых слов. По факту собранного ядра выполняется окончательный расчет.
Мы согласны с тем, что бывают виды бизнеса, где обширной семантики не собрать. Но, стоит отметить, что даже по одной услуге может быть достаточно широкое ядро. Например, репетитор по английскому языку. Одна услуга? Да! Вот только запросов мы насобирали более 500 единиц. Эти запросы преобразовались в услуги, которые заказчик тоже оказывает.
Важно учитывать, что технология оказания услуги может быть одна – обучение английскому языку, а входящих интентов (намерений пользователей) много. Каждое отдельное намерение пользователя – это отдельный кластер, который наполняется ключевыми словами для продвижения.
Можно не собирать всю семантику сразу, а проектировать постранично. Для этого мы предлагаем услугу техническое задание копирайтеру. Смысл – мы точечно прорабатываем каждую страницу (Метатеги, структура, пояснения для копирайтера – специалиста по написанию текста, технические требования к тексту и т.д.). В итоге – получается детальный план текста, который учитывает все требования поисковой оптимизации.
Формировать технические задания копирайтеру (определять вхождения ключей, структуру, объем), писать текст и размещать на странице сайта.
1 группа (кластер) в семантическом ядре – это одна страница. В среднем 20-100 запросов (с учетом lSI) Указанные в группе запросы должны присутствовать на странице в точном и разбавленном виде. Это определяется при семантическом проектировании страницы (высчитываются точные и разбавленные вхождения).
Создание ядра занимает от 5 дней. Услуга предполагает погружение в тематику клиента. В процессе работы могут возникать уточнения по вопросу включения/исключения определенного кластера.
У коммерческих запросов преобладает коммерческий интент (намерение пользователя сделать покупку). У информационных запросов преобладает информационный интент (намерение пользователя получить информацию – почитать статью, посмотреть инфографику и т.д.).
При проектировании страницы крайне нежелательно смешивать коммерческие и информационные запросы – в этом случае поиск «не понимает», что именно вы хотите предложить пользователю и не ранжирует страницы. На коммерческой странице невозможно продвигать информационные запросы (соответственно на информационной – коммерческие). Правило простое – не попадаем в интент, запрос не продвигается.
Отличия коммерческих и информационных интентов требуют детальной проработки семантики. Чтобы не допустить присутствия информационного интента на коммерческой странице мы формируем дополнительный контроль качества ядра: вручную сверяем запрос с выдачей поисковой системы.
Да. Более того, мы рекомендуем сначала собирать наиболее приоритетные для бизнеса кластеры (высокий средний чек, отлаженные процессы). В нашей работы бывали ситуации, когда после проработки ядра, технических заданий и усиления ссылками на заказчика выпадал шквал заявок, к которым бизнес не был готов. Фактически производственное предприятие полностью загружено на месяцы вперед, а заявки не остановить. SEO – это не контекстная реклама, здесь нельзя все выключить по нажатию одной кнопки.
Категорически нет. Современная методология поискового продвижения – это работа с кластером запросов, которые расположены на отдельной странице (мы продвигаем страницу сайта, а не запрос).
Невозможно продвигать один запрос «услуги бухгалтера», при этом исключая «услуги бухгалтера в Челябинске» и соответствующие ему ключи. При создании правильной структуры страницы кластеризация крайне важна (при прочих равных условиях), более вероятно, что сайт начнет расти по более низкочастотному и низкоконкурентному запросу «заказать услуги бухгалтера», затем по более частотному и конкурентному запросу «услуги бухгалтера».
Cуществуют направления, в которых объем запросов позволяет определять узкотематические кластеры и продвигать только их (не затрагивая более сложные и конкурентные запросы). Если у вас тематика с обширной семантикой (интернет-магазин, сайт услуг), мы собираем полное ядро, затем выполняем приоретизацию кластеров с наименее конкурентными запросами.
Структура сайта позволяет оптимальным образом внедрить ядро и сделать этот процесс экономически эффективным.
Во-первых – правильная структура делает сайт понятным для пользователя – улучшаются поведенческие факторы и обеспечивается рост в выдаче.
Во-вторых – формируется оптимальное внедрение ключей в документ. Например, в ряде тематик запросы по маске «производство…» определяют категорию товаров. По ним не нужно писать текст – достаточно показать наполненность категории карточками товаров/услуг и это обеспечит ранжирование и позиции в выдаче.
В-третьих – каждая тематика формирует свой, особый способ представления в выдаче (топ поисковых систем). Структура позволяет создать сайт, соответствующий требованиям выдачи (минимум – не хуже, чем у конкурентов, максимум – лучше конкурентов). Например, в ряде тематик не нужно создавать сео-оптимизированный текст, достаточно интерфейсных внедрений ключевых слов (меню, заголовки карточек товаров и других зоны включения ключевых слов).
Чтобы семантика была действительно качественной – нам нужно понять бизнес заказчика: какие услуги являются наиболее рентабельными, как ведет себя клиент, какие стратегические направления являются приоритетными на текущий момент.
Вся информация, которую сообщает бизнес – абсолютно конфиденциальна. Мы видим услугу семантики больше, чем часть процессы поискового продвижения. Фактически – это стратегический маркетинг: мы стремимся усилить текущие позиции в выдаче и обеспечить рост, в соответствии со стратегией бизнеса.
Например, у вас в ассортименте 10 товаров, а у конкурентов в среднем по категории 20-25. Если ассортимент, коммерческий фактор, не дотягивает до требований топа, сайт никогда не будет ранжироваться высоко. Сайт не соответствует входящему интенту (пользователь ищет большой ассортимент, который на сайте не представлен). Чтобы не тратить финансовые ресурсы заказчика на продвижение таких проблемных категорий мы уточняем основные вопросы по тематике бизнеса.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}